AI
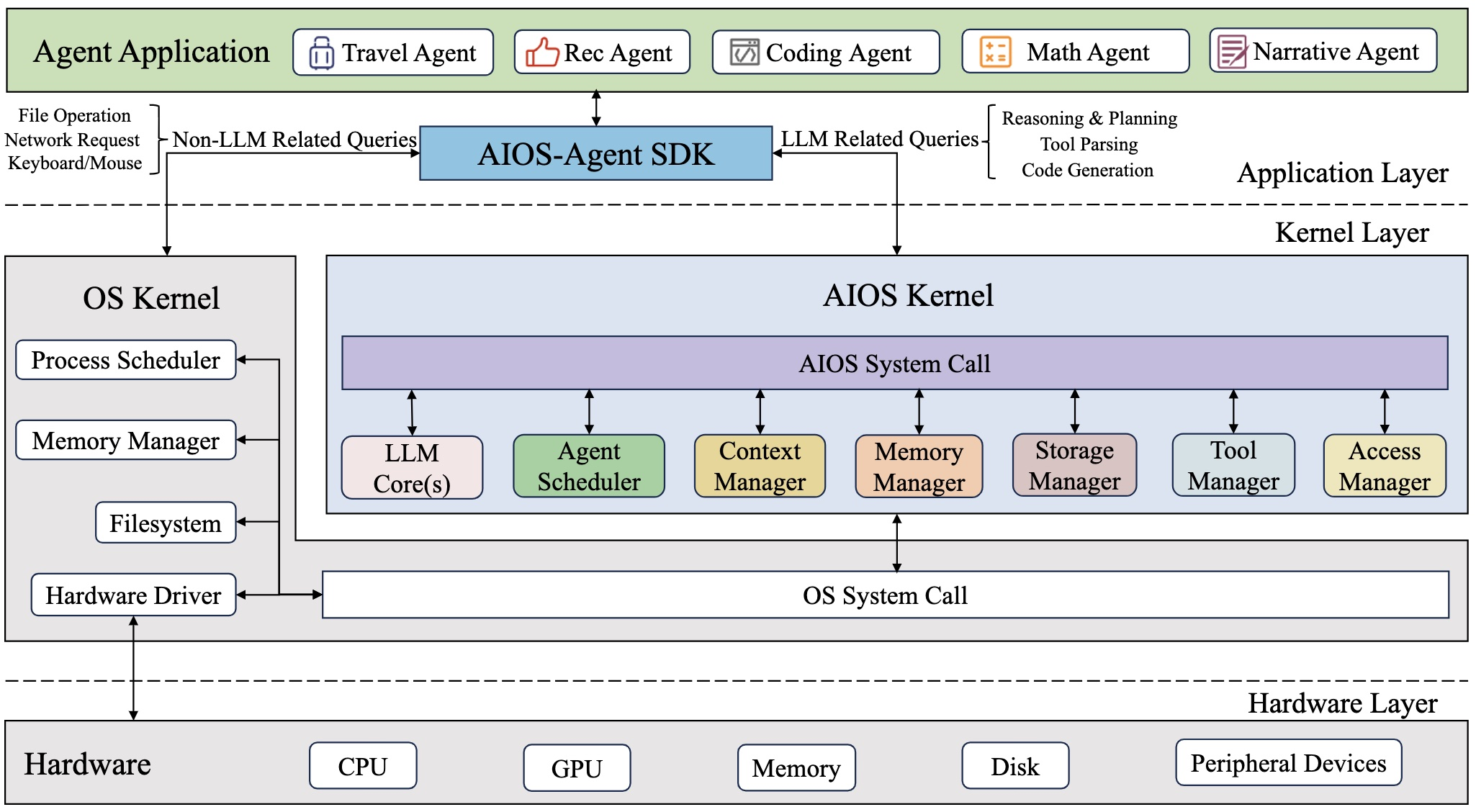
For some time now I’ve been thinking about how to deploy an agentic OS — or rather an OS kernel for research — to handle parts of routine tasks and support creativity in research and teaching. It should be capable of executing valid workflows with defined skills, and have access to learnable libraries of skills, plugins, routines, and so on (so-called research stacks). This has some similarities with the Architecture of AIOS, an “AI Agent Operating System, which embeds large language model (LLM) into the operating system and facilitates the development and deployment of LLM-based AI Agents” (Agiresearch/Aios on GitHub).
In the course of my research I came across Everything Claude Code (ECC), which brings a collection of 75 skills, 71 agents, 33 hooks, and countless commands to Claude Code. The repo is capable of executing professional research tasks semi-autonomously.
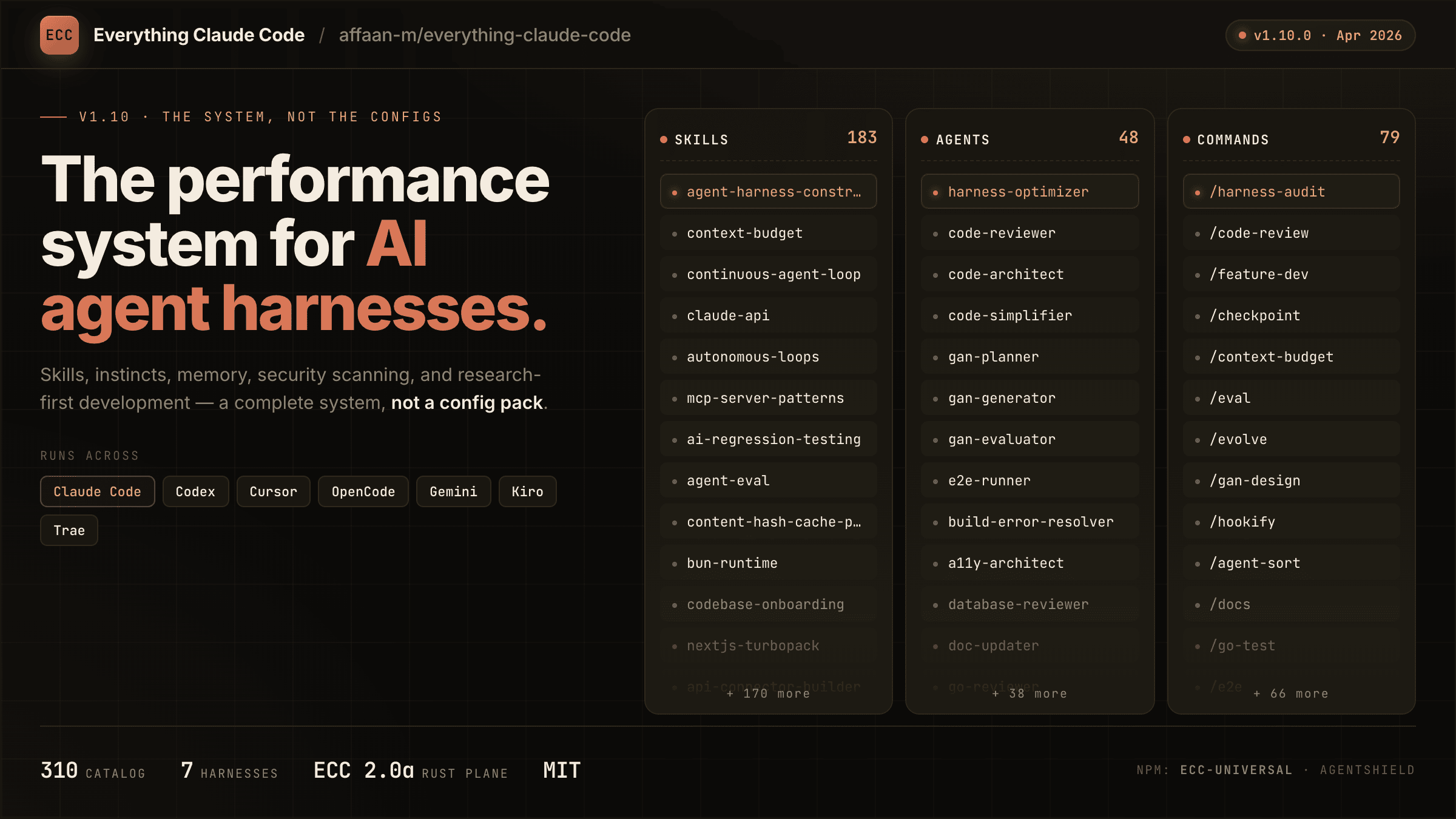
Central to the core workflow is the /everything-claude-code:plan command, which launches a specialized skill that asks clarifying questions, weighs options, and waits for explicit confirmation before a single line of code is written. This can be used both for planning a new feature in the current project and for designing a new system architecture.
The same applies to test-driven development: the /tdd workflow automatically sets up a test framework, writes tests before the implementation, and targets 80% coverage. It repeats the procedure until the desired target is reached, refining at each step.
ECC raises an interesting question: if a tool like this makes it possible to externalize good practices for working routines, does it not replace my judgment? What is the actual added value beyond saving time?
I lean toward a nuanced answer. Tools like ECC significantly lower the barrier to structured work. Beginners get a professional scaffold without years of learning experience. Those who have been at it for a long time have to exercise less discipline to maintain familiar patterns.
What no tool can replace: knowing when to deviate from the template and take a different path — for instance, to explore new scientific side roads. Running tests in a loop is very valuable, but the LLM does not know which tests are actually meaningful. And hitting some percentage-based quality target can deceive. The human work remains in reviewing goals, the means employed, and the result.
What interests me most here: the underlying principle is the same as in digital gardening. A knowledge management system externalizes implicit thinking into visible structure — making it navigable, shareable, and auditable. ECC does the same with learning experience: it externalizes intuition into executable steps.
Both work best when the person behind them understands why the structure is the way it is. A digital garden without judgment is just a filing system. An AI workflow without understanding is just automation.
I explored a similar question before in From wiki LLM to reasoning linter — AI as thinking partner, not thinking replacement.
Notes developed after watching Andrew Korshak’s video.
● Seedling
● Growing
● Evergreen